


3·
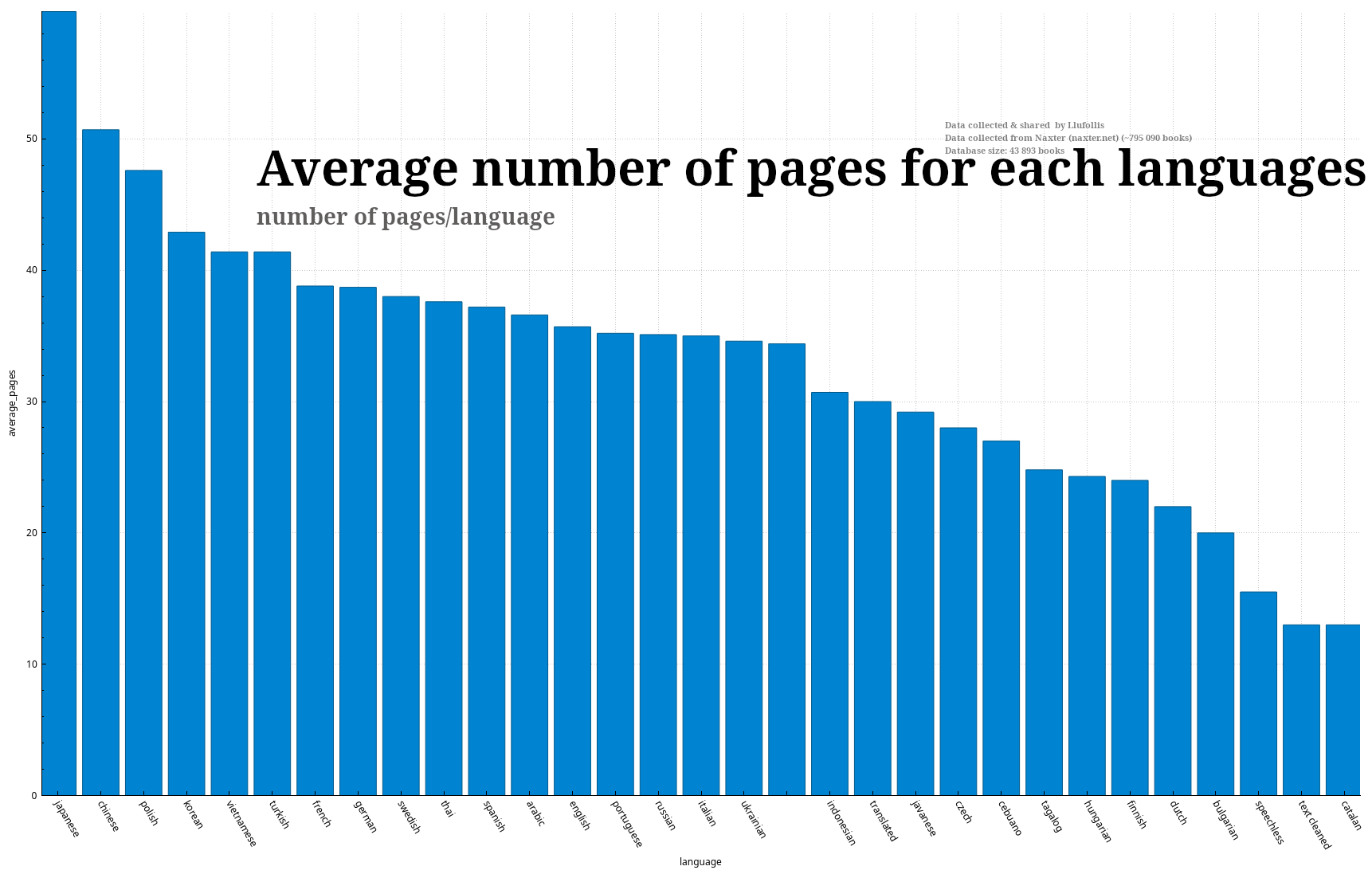
22 days agoEach entry in the database contains a language and a number of pages. I sorted all the entries by language and took the average number of pages for each of them. But it also display a major weakness, each language don’t have the same number of entries, some have thousands, others less than a hundred. I should have “normalized” the number of entry for each language and exclude languages which don’t have enough entries.

{kind=link}
if( you need CUDA ){ Use Nvidia (note that OSs officially supported by CUDA often use “old” versions of linux, like Debian 12 (6.1) or Fedora 39 (6.8), I personally use Arch); } else { Use AMD, you will have less problems and it’ll probably be easier to setup; }