
{kind=link}
via https://www.reddit.com/r/europe/comments/13chr5f/mentions_of_the_word_fascism_and_its_derivatives/
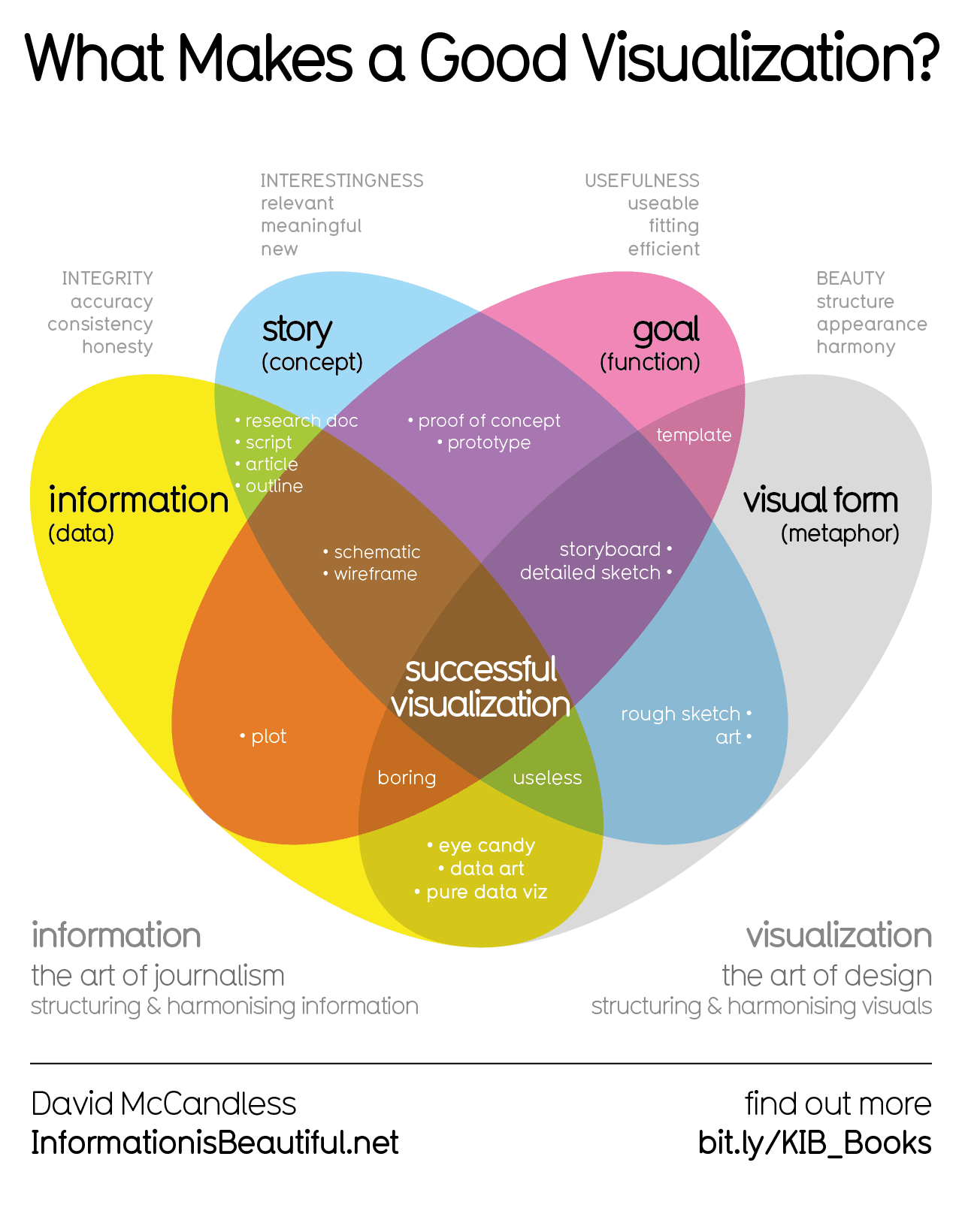
Percentage of pages mentioning “fascism” and its derivative words, from January 1938 until December 1942. Darkest blue is front page, the lightest blue is 6+ pages. Letters at the bottom are months.
Source, based on data from the Pravda Digital Archive.
Some software solutions exist, e.g. War and Peace by Tolstoy can be downloaded with metadata, ids are assigned to all characters and when one character tells something to another, this is highlighted as “x speaks to y”, and you can run a community detection algorithms on this data. I think in the paper they’ve been mentioning some proprietary software. I suspect detecting who speaks to whom is even harder.
Also, some form of crowd sourcing probably should be possible. At least collecting scans is possible on wikisource and wikimedia commons.
Probably AI language models should be pretty good in distinguishing between linguistic ambiguities.
I dream for a time when such reports as in OP post will be a matter of work for an hour or two — because data will be already collected and clean.
LLMs can’t deal with highly reflective languages at the moment. In English or Chinese you can assign tokens to entire words without having to account for word morphology (which is also why models fail at counting letters in words) but it falls apart quickly in Polish or Russian. The way models like ChatGPT work now is that they do their „reasoning” in English first and translate back to the query language at the end.