

You must log in or register to comment.
another good one to sneak in there… thai zero-width space: U+200B
cant see it, nothing reads it, and it makes everything error. : D
Hmm … we should start collecting these.
Anyone know of an existing list?
ᅠ
Oh ho! I see what you did there!
It’s the first one, the ㅤU+3164 Hangul filler, to save everyone else a comment source+browser console+copy-paste+hex editor/search.
I’m not an expert in Glagolitic, but I have a feeling that next-to-none of its letters are supposed to be invisible.
Came here to say fuck the zero width space. I spent 90 hours in the depths of solr looking for this fucker who brought down our entire search index.
I deal with shy hyphens a lot. They don’t display unless there’s a line break, so they get copied from various word docs or websites and end up in a database somewhere waiting to piss me off.
Yup
I’m guessing that they pasted code from inside Microsoft Word.
No. CMS updated to support new character set while solr did not. Not enough sanitization.
I’ve had similar “fun” with the character defaults on MySQL, from memory for a time it was Swedish by default, rather than UTF.
The right to left mark (U+2000F) can also be fun.
Before I went to the comments I wished no one mentioned that. As a DBA I fucking hate you…
i am an SDET. this character destroys DBs… i am sorry :(
Pretty much any ide will spot that. Maybe you can use it to teach your colleagues not to use a plain text editor.
I’m gonna need the vi guy to teach me how to get this functionality in nvim pls–don’t make me leave
The plugin YouCompleteMe would show a warning on that line
Thank you masterchief Veidt! (I had to do it, best name ever)
deleted by creator
You can pry my vim and nano from my cold, dead hands!
^(I use an ide sometimes)^
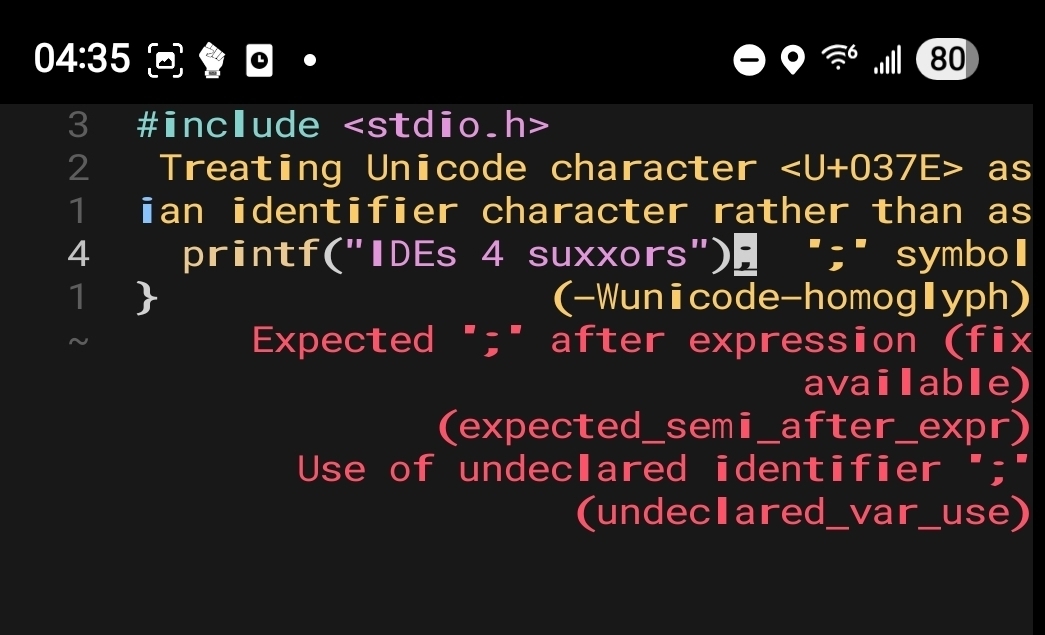
In VSCode (yeah yeah MS bad, I have to use it for work) it puts a yellow box around the charcater, which I don’t immediately recognize the meaning of and highlights the line as “identifier “blah;” is undefined”. It’s not like your gunna spend all day on it, but that could waste a couple minutes if the dev wasn’t paying close attention, which is “fun prank” territory.
Can you choose to use VSCodium instead? It’s practically identical, but isn’t controlled by MS.
The reason it’s de facto mandatory is due to some in house extensions, assuming they work with this I could, but I also don’t particularly care about my privacy on a work machine. But I will be checking this out for my personal stuff!
The extensions should work still. It even still integrates with the same extention marketplace. It’s the same software, just the open source part without the MS stuff —which honestly, I have and do use both and I don’t know what the difference is.
It’s definitely worth checking out. If it doesn’t work for you then still nothing is lost except a small amount of time, but I’m willing to bet it does.
I mean sure, but it’ll still likely leave 'em scratching their heads for a while before they go “I guess I just… replace the semicolon…?”
That’s the plain text editor Helix. In a terminal. Over ssh. On my phone. Which I can do because I’m not using a dumb IDE.
Developing on a phone sounds like one of the most unpleasant experiences I can imagine. And I include dinner with my ex.
It absolutely would be. It is, on the other hand, occasionly useful to be able to pop in and change a config file, many of which are actually Turing complete languages. What I do far more often, though, is SSH into remote, headless servers and write code there, which is exactly the same as doing it from a phone, only much more comfortable.
With screen mirroring and USB OTG mouse /keyboard it’s totally possible.
So not really on a phone, using a phone as a CPU. You may as well get yourself a computer and work in a proper IDE. You’ll be just as mobile and more productive!
CPU? It’s called a modem!!
Why yes my phone has both a CPU and a modem.
Maybe they’ve got tiny thumbs.
fr*cking rust ruining the fun


You can’t err out rust.
Okay fuck you op
IDE users pretending compilers don’t exist.
$ guix shell gcc [env]$ g++ test.cpp test.cpp:4:16: warning: `0;' is not in NFC [-Wnormalized=] 4 | return 0<U+037E> | ^~~~~~~~~ test.cpp: In function ‘int main()’: test.cpp:4:16: error: unable to find numeric literal operator ‘operator"";’ test.cpp:4:18: error: expected ‘;’ before ‘}’ token 4 | return 0; | ^ | ; 5 | } | ~Look ma, no IDE! 😸
; ;Tried to figure out which was which by googling, but it seems they are both read as semi colon, however you can see the difference in the characters. Wild
I wrote the semicolon after the weird one
If you look at the UTF definition, it seems that there are at least four of them. The weird one in your comment might actually be one of the other two because as far as I can tell, the “Greek Question Mark” looks identical to the “semicolon”.
I used
python -c 'print(chr(0x37e))' | termux-clipboard-set
This is indeed some next-level fuckery.
deleted by creator
deleted by creator
I don’t see a problem
#include <iostream> #define ; ;; int main(){ std::cout << ";\n"; }Whoa the font on the Lemmy web UI actually renders them differently!
With the “wonderful” tooling at work, we use Skype for Business. Naturally, that is not the primary place to send around code and configs, but a 1-liner or 2-liner happens.
You can’t believe the nonsense it does when you try to copy & paste it. Spaces get turned into non-breaking spaces etc. Looks completely normal when pasted directly into vim on a console, but will give “odd” error messages.
Skype still exists?
At this point, even Microsoft wants them to stop using it, but they are stubborn and try to keep it running until they turn off the lights the hard way.
Officially, no.
Any half-decent editor/IDE/command line tool will scream at you about this; plus there’s version control which should help you spot it as well.
There is no wise way to use that information.
But the foolish ones could be entertaining.
Wow!
This seems to be further evidence that the process for assigning UTF entities has been thoroughly corrupted.
You can (apparently) copy/paste this on mobile:
“;” (Greek question mark)
“;” (Semicolon)
You can even render it in HTML:
; ;And it’s included on Wikipedia, because of course it is:
Because I’m not sure what my mobile client will actually do with this comment, here’s the link to the HTML entity I used:
Also there’s plenty of other character joy to be had:
If I don’t understand what’s happening here but want to, should I research Unicode in general or something else?
Unicode is a way to encode the things that humans use to write stuff into a computer.
ASCII is for example another way, as is EBCDIC.
All these methods translate squiggles that we’ve used for centuries into something that can be represented inside a computer.
For example, the letter “A” is under ASCII represented by the number 65.
This post is pointing out that there are two characters that look identical, but have different numbers, which means that what the user sees is identical, but what the computer sees is different.
This is the basis for much tomfoolery.
This fact is actively used for phishing, as you can craft domains looking nearly identical to the original one, but leading to your IP address hosting the phishing mask.
One of my favorites was using Japanese full stop (U+3002) in place of periods in a bare IP or anywhere you would use a period in a FQDN (fully qualified domain name). Only tested in Chrome at the time, but the browser would “correct” it for you and take you to the intended page.
What exactly do you think you can do with this?
Chaotic evil linting rules
Take someone’s source code, replace all semi colons with Greek question marks and see if they can compile. But as others said, any IDE will help.
Not all! Just one or two per file.
Just the last one, right before the EOF.
Speaking of EOF, I wonder what a heredoc might do with this 😇
You’re just going to get syntax errors though
Not if you choose to replace the correct ones at the correct place and it is a compiler which automatically ignores this wrong semicolon.
You could connect two lines, which may still “work” if not split using a semicolon and are then interpreted as one single line.
You are right … but, you’re not thinking big enough.
Think … sticky tape on the bottom of a mouse.
What the fuck is that supposed to do?
Hmm … bash.
mess with whoever has the least modern ide? I’m sure there’s something else too hold on
Would probably be more effective to mess with Linux config files that use semicolons. Especially if it’s run as a daemon because Systemctl doesn’t always return helpful error messages for configuration errors.
I think most daemons would log a helpful enough error message regarding incorrect syntax e.g. if it’s a config file of variable=value; format then it wouldn’t expect two equals signs on the same line.
I too wish to see these not-so-helpful error messages (not denying just new)
would you say openRC or rc-service returns better or more helpful error messages with these kinds of things?
Remember … with great power comes … something.
Remember … with great power comes … something.
Hemorrhoids.

















{kind=link}